


RISC vs CISC
מעבדי CISC או בשמם המלא – Complex Instruction Set Computer הם מעבדים שמטרתם לבצע פעולה (או סט פעולות) במספר המינימלי האפשרי של שורות קוד Assembly.
מטרה זו מושגת ע”י מעבד המסוגל לפענח ולהריץ ISA או בשמם המלא – Insturction Set Architecture המאופיין במגוון גדול של פקודות Assembly.
ISA – בעצם מקבץ פקודות ה – Assembly שמאפיין את ארכיטקטורת המעבד המדובר, הכוונה – אילו פקודות ספציפיות כמו למשל: jmp, mov, add…המעבד “מכיר”, יודע לתרגם לשפת מכונה, ולבצע.
**ISA גם מאופיין ע”י ה – register-ים אותם הוא “מכיר” אך לא נתמקד בזה כרגע😊
מעבדי RISC או בשמם המלא – Reduced Instruction Set Computer הם מעבדים שמטרתם לבצע פעולה (או סט פעולות) בזמן ביצוע של מחזור שעון אחד – בעגה המקצועית: One Clock Cycle.
מטרה זו מושגת ע”י צמצום ה – ISA לסט פקודות מצומצם יותר – כאלו המסוגלות לבצע את מטרתן בזמן של מחזור שעון יחיד.
קצת היסטוריה – מעשייה ב – RISC ו- CISC
פרק א’ – סבא CISC
בסוף שנות ה – 70, כשמעבדי CISC רק התחילו להתפתח, זיכרון (RAM) היה מצרך ממש יקר.
Compiler-ים קיימים היו עדיין בחיתולים שלהם ולא “עשו את העבודה” כמו היום, לכן אנשים נטו לכתוב תוכניות בקוד Assembly בעצמם.
בגלל שזיכרון היה כל כך יקר, היה צריך לחשוב על פתרונות איך לשמר אותו, איך להשתמש בו בצורה הכי יעילה שיש.
הגיעו למסקנה שאפשר ליצור ISA שמורכב מ – CPU Instructions בעלות פונקציונאליות רחבה.
כלומר, פקודה אחת, שתגולם בעזרת פקודת Assembly יחידה – על אף היותה “מורכבת לביצוע” עבור המעבד, תוכל לבצע המון דברים ובה המתכנת יוכל להשתמש.
אחרי תקופה, הבינו שיש לא מעט בעיות בפתרון הנחמד הזה 😅, מכמה סיבות:
- המעבד משתמש ב – Decoder לצורך פיענוח פקודת ה – Assembly.
בגלל הפונקציונאליות הרחבה של הפקודות הן היו שונות זו מזו מבחינת קידוד/תצוגה בשפת מכונה וכ’ו…
יצירת Decoder שיצליח לפענח כל פקודת Assembly כזו, או אפילו כמה Decoder-ים, איך לומר – “היה כאב ראש לא קטן”. - הפתרון הזמני שהם מצאו לצורך ב – Decoder-ים (שגם התגלה להיות הבעיה השנייה במעבדי CISC) – היה להמציא דבר שנקרא Microcode.
בקצרה, כמו שבתוכניות קוד מודרניות מתכנתים משתמשים ב – subroutines או functions, להן ניתן לקרוא שוב ושוב – כך גם נעשה עם ה – Microcode.
לכל פקודה ב – ISA ניצור תוכנית קטנה שיוקצה לה מקום ייעודי בזיכרון ה – CPU שתורכב אפילו מ – Instructions-ים יותר קטנים, להם נקרא Microcode.
כך ל – CPU תהיה קבוצה קטנה של פקודות Microcode, אותן ניתן יהיה להרחיב ולהוסיף להן עוד ועוד Instruction-ים מורכבים יותר – ע”י פשוט הוספת תוכנית Microcode קטנה בתוך המעבד.
שוב, אחרי תקופה, הבינו שכל ה – Microcode האלו שמתווספים התחילו להיות “כאב_ראש_לא _קטן_2” – תיקון של כל “באג” ב – Microcode היה סיפור רציני כי לא היה ניתן לגשת לבצע Test-ים על הקוד בכזו קלות כמו יום.
ואז, אנשים הגיעו לתובנה שאולי אפשר אחרת 😏
פרק ב’ – RISC RISC RISC 🤩
פרט לבעיות שהתגלו במימוש הארכיטקטורה של מעבדי CISC, ועקב כך כי:
- זיכרון RAM הפך הרבה יותר זול.
- Compiler-ים הלכו והשתדרגו.
- מתכנתים החלו לתכנת פחות ופחות באסמבלי אלא יותר בשפות “עיליות” –
נעשתה קפיצת המדרגה לשימוש במעבדי RISC.
הבינו כי מבחינת ביצועים, ניתן להגיע לאותם ביצועים (ואף טובים יותר) פשוט באמצעות שימוש ביותר פקודות פשוטות בהשוואה למספר “מועט” של פקודות שבו כל פקודה מאוד מורכבת.
בנוסף, מצאו כי התדירות בה משתמשים בפקודות מורכבות אלו הקיימות במעבדי CISC, היא לא כזאת גדולה ותכל’ס העלות לגמרי עולה על התועלת.
וככה נולד רעיון ה – RISC: במקום להשתמש ב – ISA רחב שמורכב מהרבה Complex Instructions, נעבור ל – ISA צר שמורכב ממעט Simple Instructions (ובעזרתן נממש את הפונקציונאליות של ה – Complex Instructions כשנצטרך בכך).
שורה תחתונה – מעכשיו, הדגש יושם על התוכנה במקום על החומרה (כמו שהיה במעבדי CISC) – נממש את הקוד שלנו הכי יעיל שאפשר ונשאיר לאלו שכותבים ומשדרגים את ה – Compiler-ים לדאוג לתקן בעיות הקשורות ל – Microcode ולהתאמות החומרתיות.
מכאן גם מגיע השם Reduced – שכן מעתה, ה – Instructions-ים יהיו פשוטים יותר מבחינת המורכבות שלהם – Reduction In Instruction Complexity.
שימו לב, מדובר בפשטות מבחינת האופן בו החומרה תמומש במעבד (תצרוך פחות משאבים וכ’ו..) כלומר “פשטות” עבור ה – Compiler ולא בהכרח מבחינת “פשטות” בכתיבת הקוד עבור המתכנת.
למשל בואו ננתח בקצרה, את קטע הקוד הבא שכתוב ב – Assembly של מעבדי MIPS:

- קודם מתבצעת טעינה של ערכים מהזיכרון בעזרת פקודות load (או ב – Syntax של השפה: lw = load-word).
- לאחר מכן מתבצעת פעולת הכפלה ביניהם, בעזרת פקודת ה – mult בה ערך המכפלה נשמר באוגרים lo ו- hi (ה – 32 הביטים הנמוכים וה – 32 ביטים הגבוהים של המכפלה, בהתאמה).
- לאחר מכן ערך האוגר lo מועבר לאוגר t1.
- לבסוף, ערך המכפלה נשמר חזרה לזיכרון בעזרת פקודת Store Word (sw).
אם נסתכל על קוד מקביל שמבצע מכפלה ב – Assembly של 8086 (x86) אתם תבינו למה אני מתכוון:
(אמנם מדובר בפקודה מפורמט I, המבצעת מכפלה בקבוע אך לא ניכנס לזה כרגע🙃 )
הפקודה מבצעת מכפלה של ערך השמור באוגר ב – Integer ששמור במערך בזיכרון (פלוס חישוב הכתובת הנכונה כדי לגשת אליו) ושומרת את הערך באוגר היעד eax.
לחלוטין פעולה מורכבת, גם גישה לזיכרון, גם חישוב וגם שמירה באוגר היעד בפקודה בודדת!
הערה: ייתכן כי היה ניתן לבצע את הפקודות בשורות 17-18 (בקוד ה – Assembly של MIPS) בצורה יותר יעילה אך אין זה העיקרון שבאתי להמחיש.
העיקרון שרציתי להמחיש נעוץ בהבדל בין הארכיטקטורות המיוצג בתרשים הבא:
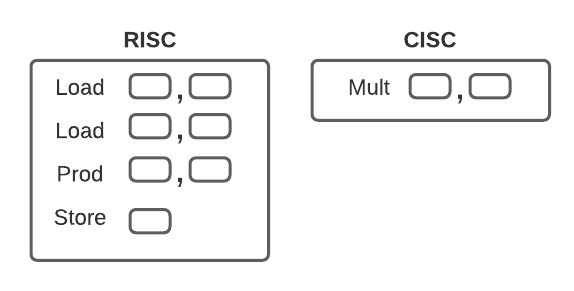
קיים הבדל מהותי מבחינת האופן שבו כל ארכיטקטורה עובדת ואפשר לומר “האסכולה” עליה היא מתבססת, נראה את ההבדל ביניהן בפסקה הבאה.
אז מה ה – Pain ומה ה – Gain בכל צד
כמו שאמרנו קודם, המניע להמצאת ארכיטקטורת ה – RISC היה העובדה הפשוטה הבאה:
“אנשים תכל’ס כבר לא כותבים ב – Assembly, למה שלא נפתח ארכיטקטורה יותר פשוטה מאשר CISC, אותה המעבד יוכל לתרגם ולבצע ביתר קלות?”
אם כך, RISC נוצרה יותר עבור אופטימיזציה ל – Compiler-ים ולא עבורנו, בני האדם.
נתמצת בקצרה את הדקויות ביניהם:
| ארכיטקטורת CISC | ארכיטקטורת RISC |
| ה – ISA מכיל פקודות שמתפרסות על יותר מ – Clock Cycle יחיד. | כל הפקודות ב – ISA אחידות, ובהכרח יסיימו לרוץ תוך Clock Cycle יחיד. |
| Hardware Centric Design – מושם דגש על ה-ISA ש”תגיע לקצה” ותשתמש בחומרה בצורה המיטבית – זה בא לידי ביטוי בשיפור החומרה עצמה: מספר Transistor-ים בחומרה לצורך מימוש יעיל יותר של ה – Instructions. | Software Centric Design – האחריות מוטלת על המתכנת לדאוג ליעילות הקוד (ואופן עבודת הקומפיילר) במקום להתחיל לדאוג לחומרה עצמה. |
| ניצול יעיל של זיכרון ה – RAM – יש צורך לטעון לזיכרון פחות פקודות (שכן כל פקודה “מורכבת” ובעצם נותנת פונקציונאליות רחבה). | ניצול פחות יעיל של זיכרון ה – RAM – יש צורך לטעון לזיכרון יותר פקודות שכן כדי להגיע לפונקציונאליות מסוימות, נידרש ליותר פקודות. |
| תומך ב – Microcode – ניתן להתייחס לפקודה אחת כתוכנית קטנה בפני עצמה. באותה נשימה, פקודות רבות שונות זו מזו בייצוג שלהן, בגודל המשתנים ובגודל הפקודה. | שכבה אחת של פקודות, כולן באותו fixed size. |
| Memory-To-Memory – יוסבר ממש בקרוב. | Register-To-Register – יוסבר ממש בקרוב. |
| קיימת תשלובת של – Addressing Modes. | קיימים Addressing Modes בודדים ומוגדרים מראש. |
חידוד קטן בנוגע למינוח: Addressing Modes
Addressing Modes מייצגים את הדרכים השונות לביצוע Fetching של ה – Data, למשל:
- שימוש במשתנה constant שמייצג את כתובת אותה נמשיך לבצע.
- שימוש בכתובות Relative למשל, במעבדי MIPS קיים Addressing Mode הקרוי – PC-Relative העובד בשיטה זו.
- שימוש בכתובות Absolute למשל, במעבדי MIPS זה מיושם בחישוב כתובות ה – Jump.
- וקיימים נוספים…
נקודות חשובות שעד עתה פחות הוזכרו:
Pipelining
קונספט מאוד מרכזי שנוצר בעקבות היווצרותם של מעבדי RISC הוא Pipelining (או הצנרה, כן אני יודע, המינוח בעברית 🤢).
אני אתן דוגמה שבזמנו המרצה שלי בתואר סיפר לנו, שממחישה את העיקרון הזה ממש יפה:
יש מכבסה תעשייתית גדולה ובה העובדים מכבסים בגדים שמגיעים אליהם.
יש ערמת בגדים גדולה אותה העובדים במכבסה צריכים לכבס.
השלבים שהם מבצעים:
1. לוקחים מהערמה הגדול תת ערמה קטנה יותר ומכניסים אותה למכונת כביסה פנויה.
2. ברגע שמכונת הכביסה סיימה, מוציאים את הבגדים הנקיים ומעבירים אותם למייבש.
3. ברגע שהמייבש סיים מוציאים את הבגדים הנקיים ושמים אותה על שולחן הקיפול.
4. בשולחן הקיפול, מקפלים את הבגדים.
5. משולחן הקיפול, מפצלים את הבגדים בהתאם ללקוחות בארון הארגון.
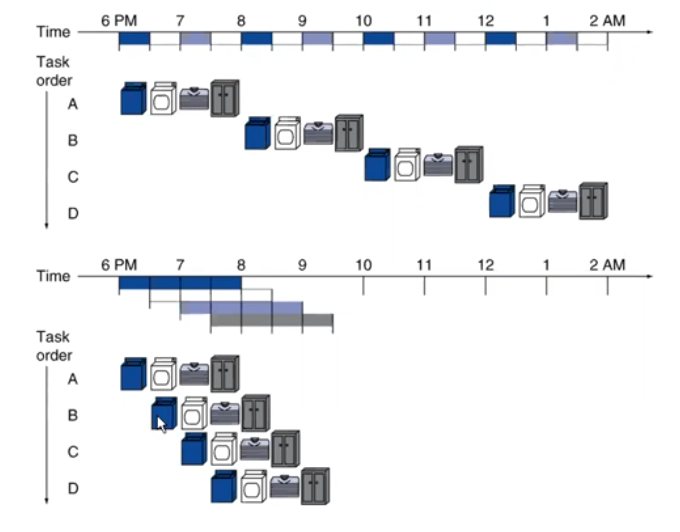
אם נקביל תהליך זה לביצוע הפקודות במעבדים, אז במעבדי CISC התהליך בעבר התבצע בצורה כזו:
רק ברגע שפקודה אחת הסתיימה לחלוטין, זו שאחריה תתחיל להתבצע.
למשל, מכונת הכביסה סיימה את העבודה שלה שלקחה חצי שעה, עתה נתחיל את השלב השני ונעביר את הבגדים למייבש.
המייבש סיים את העבודה שלו שלקחה גם כן חצי שעה, עתה נעביר את הבגדים לשולחן הקיפול וכך הלאה…
בתהליך עבודה זו, משך ביצוע התוכנית הוא סכום הזמנים של כל השלבים – במילים אחרות מאוד לא יעיל.
מה שכן, אם נצליח ליצור מצב בו משך ביצוע הזמנים של כל השלבים הוא זהה (או לפחות באותם סדרי גודל) נוכל לרתום את עיקרון ה – Pipeline לטובתנו.
מה הכוונה?
אם כל הפקודות יקחו אותו פרק זמן לביצוע (כאן אנחנו מבינים מאיפה הגיע התכונה של One Clock Cycle), נוכל למשל, אחרי שערמת הכביסה סיימה את שלב הניקוי במכונת הכביסה, נוכל להעביר אותה למכונת הייבוש ובינתיים להכניס ערמה חדשה לשלב הניקוי במכונת הכביסה – כלומר, לא נצטרך לחכות שהערמה הראשונה תסיים את כל 5 השלבים כדי לקדם את הערמה השניה והשלישית במעלה ה – Pipeline של תהליך הניקוי😃.
תהליך זה מתאפשר עקב העובדה כי כל שלב (או במונחים של מעבדים, כל פקודה) לוקחת את אותו פרק זמן ולא יווצר “צוואר בקבוק” בו פקודה או מספר פקודות “מחכות” לפקודה כלשהי בגלל שהיא לוקחת משמעותית יותר זמן מהאחרות.
מעצבי ארכיטקטורת ה – RISC הבינו עיקרון זה, ומכאן אנחנו מבינים מאיפה הגיעו התכונות שדיברנו עליהם קודם: One Clock Cycle לכל פקודה, כל הפקודות יהיו בגודל זהה (של 32-bit ) לצורך ביצוע Decoding בזמן *זהה (טוב נו יחסית זהה) לכל פקודה, ושלל תכונות נוספות שראינו קודם.
Load/Store Architecture לעומת Memory-To-Memory Architecture.
ארכיטקטורת RISC מכונה גם ארכיטקטורת Load-Store.
Load ו – Store הן משפחה של פקודות המאפשרות גישה לזיכרון הראשי (RAM) לצורך קריאה וכתיבה.
על מנת שנוכל לרתום לטובתנו את עיקרון ה – Pipeline חשוב היה לוודא שכל הפקודות יתבצעו באותם סדרי גודל מבחינת זמן הביצוע שלהם.
לכן, בארכיטקטורת RISC שלב ה – Loading/Storing לזיכרון הראשי מקבל ממש שלב נפרד במעלה ה – Pipeline.
פקודות אלו מתוקף העובדה שהן ניגשות לזיכרון ה – RAM ולא עובדות עם הערכים שכבר שמורים באוגרים יקחו יותר זמן, על כן על מנת לשמור על “אותו סדר גודל לכל פקודה” אין ברירה אלא לתת להן שלב נפרד ב – Pipeline שלנו.
במעבדי CISC לעומת זאת, פקודות מסוימות יכולות לבצע load ל- data מהזיכרון הראשי, לבצע עליו פעולה של addition/ subtraction/ multiplication וכ’ו…וישירות לכתוב את הזיכרון חזרה לזיכרון.
ומכאן השם Memory-To-Memory או כמו שאני מתאר אותו “חוצה זיכרון”.
אולי זה נשמע “יותר יעיל” אבל מבחינת מימוש הפקודות ב – Pipeline, פקודה כזו תיקח הרבה יותר זמן משאר הפקודות ולכן בגישת RISC עדיף לפצל אותה למספר פקודות נפרדות.
כל פקודה תתבצע בשלב נפרד, ושאר הפקודות אחריה יוכלו להמשיך להתבצע מבלי שיווצר עיכוב.
יותר מכך, קיום פקודה כל כך compound שמורכבת מ: קריאה מהזיכרון, ביצוע פעולה ב- ALU (חיבור/חיסור וכ’ו..) וכתיבה חזרה לזיכרון זה ממש מנוגד לכל עיקרון הפשטות שעליו מתבססים מעבדי RISC – במעבדי RISC כל הפעולות האלו יתבצעו על המידע ב – Register-ים עצמם – ומכאן השם Register-To-Register.
שלב ה – Load מהזיכרון הראשי ושלב ה – Store חזרה לזיכרון הראשי יבוצעו בשלבים נפרדים – כמו ששלב החיבור/חיסור/כפל וכ’ו.. יתבצע בשלב נפרד שיתבצע ב – ALU, בו הערך תחילה יישמר חזרה ב – Register וייכתב חזרה לזיכרון בשלב נפרד.
Multiple Registers
דיברנו קודם על זה שמעבדי RISC פחות יעילים מבחינת ניצול ה – RAM שכן נדרשות יותר “פקודות פשוטות” לביצוע פעולה כלשהי, שבמעבדי CISC היינו יכולים לבצע בהרבה פחות פקודות – על כן נדרש לטעון יותר פקודות לזיכרון ה – RAM.
הפתרון שארכיטקטורת RISC נותנת לבעיה זו הוא פשוט שימוש ביותר Register-ים.
החבר’ה החריפים שם זיהו, שרוב הפקודות פשוט קוראות וכותבות Data מהזיכרון בשביל שיהיה ניתן לבצע פעולות על ה – Data הזה בפעולות אחרות.
אם כך, למה שלא פשוט נקצה יותר אוגרים לרשותו של ה – CPU ?
ככה בכל פעם נוכל להביא יותר מידע מהזיכרון שיישמר ב – Register-ים ונחסוך לעצמנו כמה שיותר גישות לזיכרון.
*נקודה למחשבה: אם כך, למה שלא נוסיף כמות ממש גדולה של Register-ים ומעבדי RISC מסתפקים רק ב-31…נקודה למחשבה 😉
צעד זה דרש הרבה ניתוח מעמיק של מתי נצטרך לשמור מידע ב – Register, מתי נצטרך לכתוב אותו חזרה לזיכרון ודקויות רבות נוספות – בעיקר הצריך שיפור מאסיבי של יכולות ה – Compiler-ים.
כאן נכנס לתמונה היתרון שבמעבדי RISC ה – Addressing Modes הוא הרבה יותר מצומצם וזה מה שאיפשר לבצע שינויים אלו ביתר קלות – בכתבה הנוכחית לא ניכנס לזה.
התשובה של מעבדי CISC “לכל היופי שבמעבדי RISC”
החבר’ה המתחרים של מעבדי CISC כמובן שלא ישבו בשילוב ידיים והחלו להטמיע עקרונות ומאפיינים של מעבדי RISC במעבדים שלהם🦊.
הם הבינו שכדי להישאר במשחק, הם חייבים למצוא דרך לבצע Pipelining גם במעבדים שלהם – מה שהתברר כקשה להחריד בארכיטקטורה שהייתה באותה תקופה.
הפתרון שלהם היה לממש את החלק הפנימי של מעבדי CISC שיהיה כמה שיותר דומה למעבדי RISC.
זה נעשה ע”י ביצוע Decoding לפקודות בארכיטקטורת CISC ולאחר מכן פירוקם למספר פקודות פשוטות יותר שנקראו Micro-operations.
כעת, כמו פקודות במעבדי RISC, ה – Micro-operations האלו יוכלו להיכנס לצנרת (כן אני יודע, ל – Pipeline) בגלל שזמן מחזורי השעון שדרושים לביצועם הוא יותר צפוי ויחסית באותם סדרי גודל.
לא נרחיב יותר מידי על Micro-operations למרות שאני חושב שזה נושא ממש מעניין 😍, מוזמנים להעמיק יותר בקישור הבא: https://erik-engheim.medium.com/what-the-heck-is-a-micro-operation-e991f76209e
RISC-V
במעבר חד, נעבור למעבדי RISC-V.
לא יודע אם שמעתם או לא, אבל ה – Buzz word הקטנטן הזה, צף ועולה לאחרונה לא מעט (טוב נו, לפחות בכתבי טכנולוגיה) ויש לכך סיבה חברים.
מעבדי RISC-V תוארו לא מעט בתור ה – “Linux of CPU’s” אבל ה – Open-Source-יות זה לא הדבר הכי מגניב שלו 😨.
כמו שעקרון ה – Open-Source תפס את העולם בסערה בתחום התוכנה, לאט לאט אנחנו מתחילים לראות שהקונספט הזה זולג וגולש לעוד תחומים וביניהם תחום החומרה.
בין היתרונות של מעבדי RISC:
- ה – ISA שלהם הוא non-incremental, אוקיי דן, מה זה אומר? 🤨
ל – ISA מודרנים אחרים כגון: x86, MIPS ו- ARM ממשיכים להתווסף פקודות נוספות עם הזמן, כך שעם הזמן ה – ISA ממשיך לגדול ולתפוס יותר נפח, למשל ה – ISA של מעבדי x86 מכיל מעל ל-1500 פקודות שונות, כשבפועל חלק נכבד מהם כלל לא בשימוש.
מעבדי RISC-V עם זאת, מתבססים על extensions, פקודות שלא בשימוש לא ישארו…מה שמשאיר מעבדי RISC-V עם כמות פקודות ממש מצומצמת. - בגלל המודלריות של מעבדי RISC-V ניתן ממש למחוק כל פקודה ובכלל כל דבר שמעלה את המורכבות של הרצת התוכנית, יש לכך מספר יתרונות:
- מאוד קל לממש מעבד של RISC-V וזה יכול להתבצע בעזרת ISA מצומצם נורא ומספר מועט של Transistor-ים.
- בזכות הנקודה הקודמת, אפשר להגדיל את ה – Clock Frequency שזה מה שבעצם מעלה את ביצועי המעבד (קצת יומרני לומר זאת כך, כי זה מושפע מעוד גורמים, אך זה ללא ספק פקטור מכובד 😇).
ונקודה אחרונה בהקשר של מעבדי RISC-V:
ה – RISC-V Foundation, בכלל לא מייצרת מעבדי RISC-V, רגע מה?
מה שהיא כאן מייצרת זה Specification שזה מעין “חוזה” בין אלו שמתכוונים להשתמש ב – Specification הזה, שאלו בעצם: מפתחי תוכנה, מפתחי חומרה ועוד…לבין ה – RISC-V Foundation.
ב – Specification הזה הם בעצם מתחייבים שמעבדי ה – RISC-V שלהם יתאימו ל – Specification שסופק להם.
ומה שעוד יותר מעניין, שאף אחד בכלל לא מחייב אותם “לעמוד בחוזה” הזה, אף אחד לא מאיים לתבוע אותם אם לא יעשו כך וכ’ו וכו’…
אם כך, מה גורם להם עדיין לרצות לעמוד בחוזה😏?-> לא ציפתם שאתן לכם את כל התשובות אהה?
האם יש בכלל הבדל בין המעבדים ולאן אנחנו הולכים…?
עם כל מה שדיברנו קודם, זה קצת נראה שההבדל בין ארכיטקטורת CISC לארכיטקטורת RISC דיי מיטשטש לא?
החבר’ה של CISC מתחילים להטמיע Micro-operations כדי לעבוד בצורת Pipeline..החבר’ה של RISC (או לפחות חלקם) מתחילים להטמיע טכנלוגיות כמו: Compressed Instruction Sets ו- HyperThreading שיותר נפוצים במעבדי CISC (נושאים אלו לא צויינו בכתבה לצורך הפשטות) ונראה שההבדלים, לפחות הגלויים לעין, קצת נשחקים.
עם זאת, ה – Core שמייחד כל ארכיטקטורה נשאר זהה
- מעבדי RISC מאופיינים בפקודות Fixed-Size לעומת מעבדי CISC.
- מעבדי RISC יותר מתבססים על סטנדרטיזציה של הפקודות ואיכלוס ה – Pipeline בעוד מעבדי CISC לעיתים מתבססים על טכניקות עזר למילוי ה – “חורים” הריקים שנוצרו ב – Custom Pipeline המאפיין אותם.
- האבחנה החד משמעית בין האסכולה של Load/Store המאפיינת מעבדי RISC שבהם הגישה לזיכרון מתבצעת בעזרת פקודות ייעודיות וספציפיות ורק הן עושות זאת.
לעומת האסכולה של Memory-To-Memory המאפיינת מעבדי CISC בהם פעולה כמו: גישה לזיכרון, חישוב כתובת או ערך, ואז שוב כתיבה לזיכרון יכולה להתבצע באותה הפקודה. - ריבוי Register-ים לצורך מניעה של גישות מרובות לזיכרון באסכולה של מעבדי RISC לעומת מספר Register-ים מצומצם יותר בגישת מעבדי CISC.
משפט לסיכום:
בעוד מעבדי RISC בעצם לוקחים את כל ה – Heavy Lifting ומעבירים אותו ל – Compiler מה שתורם לשיפור מובהק בביצועים, מעבדי CISC מאפשרים לנו לבצע פעולות יותר מורכבות כמו גישה לזיכרון ב – Memory Access Modes שונים, מה שללא ספק נותן לנו מענה בהרבה נקודות אחרות.
אז לאן אנחנו הולכים בעצם ?
- מתברר שלא כל ה – ISA “נולדו שווים בצלם אלוהים” וה – ISA של מעבד מסוים יכולה להשפיע בצורה משמעותית על האופן שבו יתבצע ה – Design של ה – CPU עצמו – מבחינת חומרה.
ה – ISA הספציפי שבו נבחר להשתמש יכול לפשט את תהליך ה – Design של יצירת מעבד High Performance שצורך כמה שפחות משאבים. - זה למה בשנים האחרונות Apple רוצים ליצור Tailor Made Solutions למחשבים/סמארטפונים שלהם עם Hardware ייעודי שמסוגל לתת מענה בתחומים כמו: Machine Learning, Encryption, Face Recognition ועוד.
בעוד שהחבר’ה של Intel עם מעבדי x86 המתחרים נאלצים לעשות את כל זה ב – External Chip – בגלל ארכיטקטורת ה – CISC עליה הם מתבססים – Apple מכוונים לעשות הכל ב – large integrated circuit או במינוח אחר – System on a Chip (SoC). - ה – shift בגישה הזו כבר הגיע מזמן לסמארטפונים שכן מפאת גודלם אין להם את הפריווילגיה לעוד external chip (כל הרכיבים וביניהם: CPU, GPU, Memory, Specialized Hardware ונוספים) הכל חייב להיות ממומש ב – Circuit יחיד וזה למה ARM מאוד דומיננטית בשוק הסמארטפונים (מתבססת בעיקר על מעבדי RISC).
- אנחנו כבר רואים לאחרונה שגם laptop-ים מתחילים להתבסס על Tight Integration שכולה ממומשת ב – Integrated Circuit יחיד – זה נותן שיפור מורגש ב – Performance, והצעד הבא זה שגם מחשבי PC יתחילו להיות ממומשים באסכולה זו.
אז על מה דיברנו, על מה לא (וממש כדאי לכם לקרוא)
- ראינו את ההבדלים באסכולה ובמימוש (לפחות ב – High Level Overview) של ארכיטקטורת RISC לעומת ארכיטקטורת CISC.
- גילינו קצת על ההיסטוריה של מעבדי CISC ולמה נוצרו מעבדי RISC.
מה שכן, בטח שמתם לב שנתח השוק של מעבדי CISC עדיין נורא גדול, עם כל היתרונות של RISC – יש לכך סיבה שנעוצה ברכילות עסיסית בהקשר למעבדי x86 – אם באתם ל – Gossip חברים, זה מה שאני ממליץ לכם לגגל קצת😋 - הצגנו הרבה יתרונות של מעבדי RISC והשוונו אותם למעבדי CISC, יחד עם זאת נגענו בהרבה עקרונות מפתח בעולם הארכיטקטורות בהם:
- Pipelining.
- Load/Store Architecture לעומת Memory-To-Memory.
- Multiple Registers לעומת Limited Number of Registers.
- דיברנו בתמציתיות (ואפשר לדבר המון! על הנושא הזה) על ארכיטקטורת RISC-V העולה, שמספקת בעצם: Tailor Made Chips – > אתה תבחר אילו Instruction Set Extension נכללים ב – ISA שלך (טירוף!)
- דיברנו בקצרה, לאן מועדות פנינו לפחות בתקופה הקרובה – התחום הזה כל כך דינאמי שאולי בעוד מספר שנים נגלה שה – Shift יתבצע בכלל לטכנולוגיה עם אסכולה אחרת לחלוטין 🙂
- חשוב לי לציין גם, את הדברים שעליהם לא דיברנו כי דווקא זה החלק היותר טריקי שקשה לעלות עליו לבד:
- אמנם ציינו את ה – Buzz Words האלה בקצרה בכתבה, אבל הן עולם ומלואו ומי שהתחבר לכתבה ממש יאהב לקרוא עליהן: Microcode vs Micro-Operations.
- גישות הייעול הבאות, עם לקיחת היבט ה – Security בחשבון, שנלווה אליהן: Hyper-Threading vs Hardware-Threading.
- אמנם דיברנו על ה – Pipeline אבל יותר בצורת אנלוגיה למכבסה תעשייתית, אך יש שם עוד המון דקויות טכניות שחובה לדעת – מתוקף היותן עקרונות הבסיס לעבודת מעבדי RISC בפרט ומעבדים בכלל.
ה – Pipeline מחולק ל-5 שלבים: Fetch, Decode, Execute, Memory, Write-Back,
ה – Pipeline יודע לטפל בסוגיות של Data-Hazards ו – Control-Hazards שנוצרים בעקבות ה”מקביליות” שהוא מאפשר ועוד ועוד – בקיצור עוד עולם ומלואו – (סמיילי נרגש). - ההבדל בין Latency ל – Throughput – לא נושא גדול מידי אבל חשוב לחדד את הסוגיה הזו.
גולת הכותרת, “דנוס, טחנת לנו את המוח פה שעתיים אבל איפה נכנס ה – Cache?”
ה – Cache מקבל נפח נורא מרכזי בימינו בטכנולוגיות השונות וכלל לא דובר כאן…
ספוילר, הוא מקבל גם נפח מרכזי בהקשרים של ארכיטקטורות מעבדים – ממליץ בחום לקרוא ולהעמיק בו.
References
טוב הכתבה הגיעה לסיומה, נעזרתי בלא מעט מקורות בדרך כדי להציג את התמונה הרחבה (יחסית ) שרציתי, לא מן הנמנע שאתן להם את הקרדיט שמגיע להם:
- בלוג נהדר של Erik Engheim – כתוב בצורה מעולה ומכסה המון! נושאים בהקשרים של ארכיטקטורת מעבדים:
https://medium.com/swlh/what-does-risc-and-cisc-mean-in-2020-7b4d42c9a9de - דף web תמציתי וקולע על ההבדלים בין RISC ל- CISC של אונ’ סטנפורד:
https://cs.stanford.edu/people/eroberts/courses/soco/projects/risc/risccisc/ - כתבות נחמדות נוספות שלקחתי מהן השראה בכמה נקודות:
https://www.microcontrollertips.com/risc-vs-cisc-architectures-one-better/
https://www.baeldung.com/cs/risc-vs-cisc - הספר Computer Organization And Design שנכתב ע”י David A.Patterson ו- John L.Hennessy – איתו למדתי חלק מהחומר המוצג כאן, במהלך התואר.
Very nice post. I certainly appreciate this site. Keep it up!
I don抰 even know how I ended up here, but I thought this post was good. I don’t know who you are but definitely you’re going to a famous blogger if you are not already 😉 Cheers!