אם בעבר היינו לוקחים שרת, מתקינים את התלויות ומריצים את האפליקציה, היום כדי להנגיש את האפליקציה ולהרוויח את היתרונות של מיקרו סרוויסים וקוברנטיס יש צורך בקבצי קונפיגורציה המתארים את הפיצ’רים בקוברנטיס שבהם אנחנו רוצים להשתמש. איך אנחנו רוצים שהאפליקציה תהיה מונגשת ואיך אנחנו רוצים שהאפליקציה תתנהל במצב רגיל ובשדרוג.
הבהרה: בכתבה לא נדבר על אפליקציה ששומרת עליה תוכן למשל דאטא בייס, נתמקד באפליקציה שהיא stateless כלומר ללא מצב, למשל שרת ווב.
בנוסף הכתבה תתמקד רק על הצד הקוברנטיסי ולא על הקוד של האפליקציה עצמה.
אז מה זה בעצם יתירות ולמה היא חשובה כל כך? יתירות על פי הגדרה היא:
כפילות המשמשת למניעת כשל או קריסת המערכת.
היתירות היא אחת התכונות החזקות בקוברניטיס המקנות יציבות וזמינות לאפליקציות שרצות על גביה. בכתבה נלמד את היכולות הקיימות ואיך לנצל אותן בצורה מיטבית.
לפני שנתחיל לכתוב את קבצי הקונפיגורציה של האפליקציה שלנו נשאל שאלה פשוטה. איך קוברנטיס יודע מה מצבם של האפליקציות שהוא מריץ?
למשל, האם האפליקציה מוכנה לקבל בקשות?
האם האפליקציה איבדה יכולת לתקשר עם הדאטא בייס שלה או שהוא נכנס ל Deadlock?
בשביל זה יש רכיב שנקרא kubelet (נדבר עליו לעומק בפוסט אחר) שיודע לעשות דבר שנקרא probe. הprobe יכול לדגום על ידי בקשת HTTP או TCP למקום מוגדר, ויחזיר תשובה תקינה אם האפליקציה מוכנה.
בקטגוריה הזו יש 3 סוגים שונים.
Readiness probe – מגדיר אם הpod מוכן לקבל בקשות. אם הבדיקה נכשלת בינתיים לא נעביר בקשות מהמשתמש לpod הזה. כשהדגימה תקבל תשובה של הצלחה הpod נכנס למצב מוכן והוא יכנס תחת מאזן העומסים של ה service ויקבל בקשות.
Liveness probe – מגדיר האם הpod במצב תקין או שגוי. במידה והוא מחזיר מצב שגוי יתבצע איתחול לpod .
Startup probe – מתאים לאפליקציות שלוקח להם זמן רב לעלות. הדגימה בודקת מתי אפשר להתחיל להריץ את הprobes האחרים.
עכשיו שאנחנו יודעים איך להעביר לקוברנטיס את מצב האפליקציה שלנו, נגדיר את הרכיבים שאנחנו צריכים בקבצי קונפיגורציה של האפליקציה.
Deployment
Probes
Requests\Limits
Upgrade strategy
Service
Type
Pdb
Deployment:
קובץ הקונפיגורציה של ה Deployment מתאר איך האפליקציה צריכה להתנהג בתוך קוברנטיס.
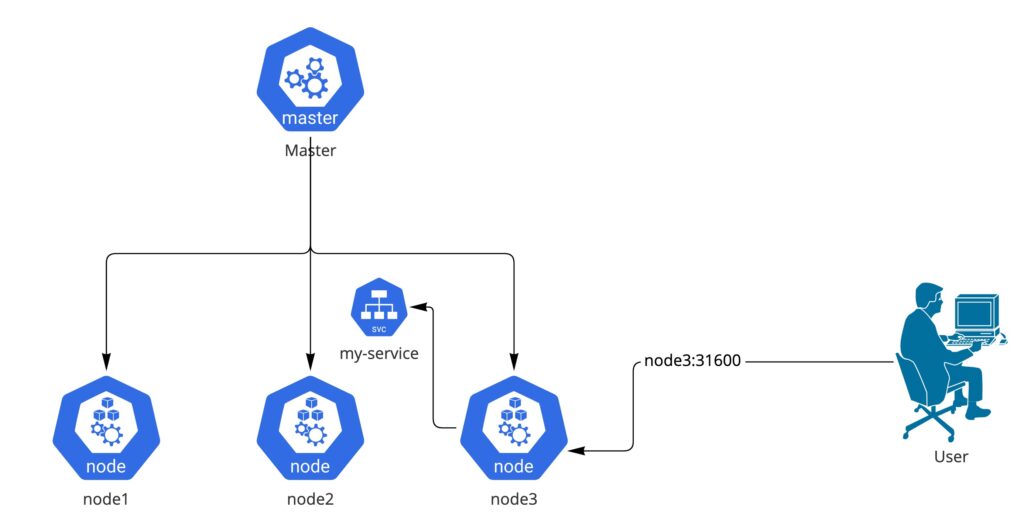
נזכיר שתפקיד הservice הוא להיות מאזן עומסים מעל הpodים והוא נקודת הגישה לאפליקציה.
ישנם שני כיוונים שמהם צורכים את המיקרו-סרביסים:
מתוך הcluster – למשל רכיב צד שרת. הפניות אל רכיב כזה לא נעשות ישירות מהמשתמש אלא מרכיב מתווך שנמצא גם כן בתוך הcluster.
מחוץ לcluster – למשל רכיב צד לקוח. הפניות אל רכיב כזה נעשות ישירות מהמשתמש.
ברירת המחדל של service בקוברנטיס הוא clusterIP, כלומר לחשוף את האפליקציה רק בצורה פנימית דבר שמתאים לסרביסים מהסוג הראשון בלבד.
במצב של אפליקציה מהסוג השני שרוצים לחשוף אותו החוצה ישנם 2 אופציות:
NodePort
LoadBalancer
הראשון NodePort נותן פורט שיהיה נגיש מעל כל שרת בcluster למשל אם נפנה לnode3 בפורט 31600 הוא יפנה אותנו ל service my-service
השני LoadBalancer נותן IP חיצוני שנגיש מכל מקום. בכל ספק שירות קוברנטיס הדבר ממומש בצורה קצת שונה אך התוצאה הסופית זהה.
בנוסף, יש אפשרות לחשוף את האפליקציה בצורה חיצונית באמצעות Ingress. Ingress הוא לא type אמיתי אלא דרך להנגיש מחוץ לcluster באמצעות רכיב נוסף(לא נרחיב עליו כעת).
Pdb:
אחד היתרונות הבולטים בקוברנטיס זה שהתשתית היא לא חייבת להיות סטטית, כלומר ניתן להחליף ללא שום מאמץ את השרת שעליו רצים הקונטיינרים.
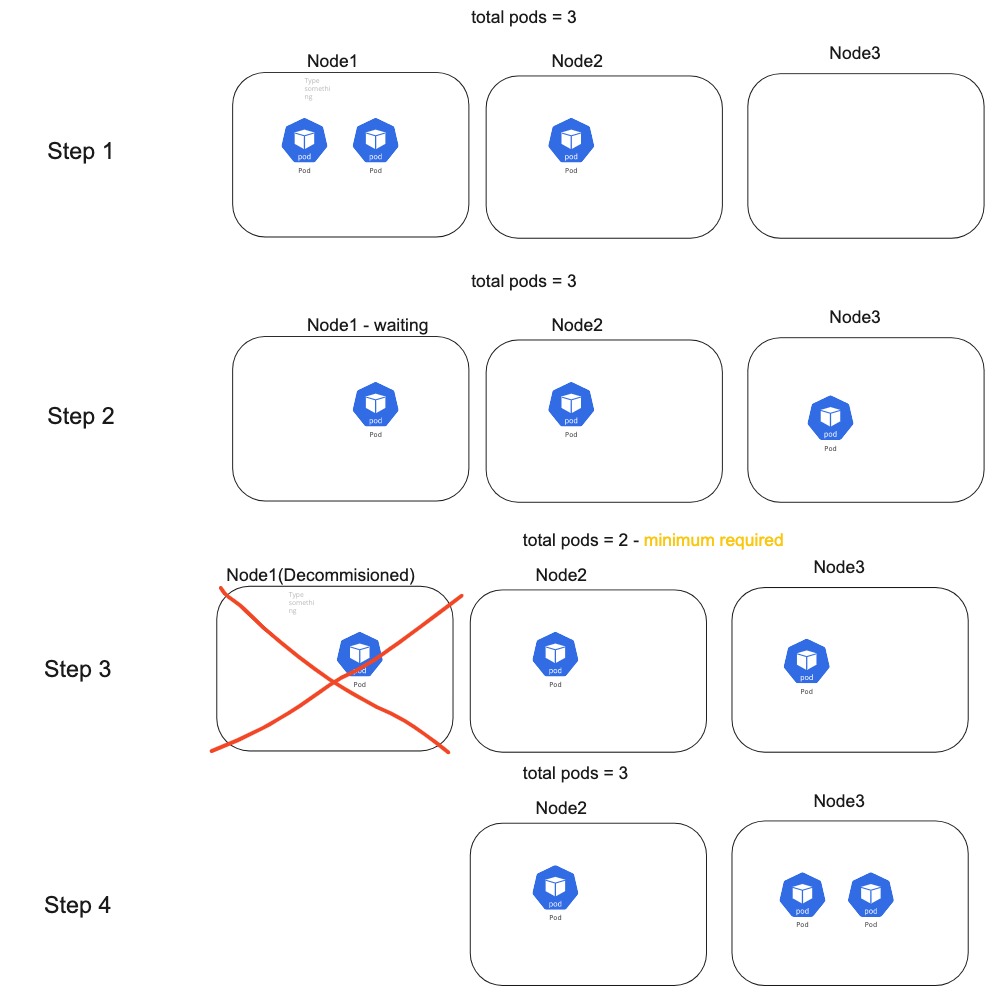
מצב זה יכול ליצור מצבים בעייתים, למשל אם יש לנו deployment עם 3 pods ולצורך תחזוקה מורידים את השרת node1:
בשלב השני יש מצב שבו יהיה לנו כמות podים קטנה משמעותית מהכמות הרצויה עד שהם יעלו בשרת אחר, מצב שיכול לפגוע באיכות השירות שאנחנו מספקים.
נראה שהשתמשנו שוב פעם בlabel כדי לשייך את הpdb לdeployment מסוים.
בנוסף הגדרנו שלא יכול להיות מצב שבו יהיה פחות מ2 podים בו״ז ולכן הורדת השרת תקבל השהייה כד למצב שבו המינימום הנדרש יתקיים:
במצב זה שלטנו על המצב ולא נתנו לשירות שלנו להיפגע באופן משמעותי.
הערה: חשוב לדעת שאם נגדיר שצריך 100% מהpods למעלה כל הזמן זה ימנע להוריד שרתים בכלל, ולכן לא מומלץ להגדיר pdb עם הגדרות כאלה.
לסיכום: כאשר אנחנו רוצים לעלות לפרודקשן חשוב לדאוג להנגיש בצורה נכונה ומתאימה את השירות. בנוסף יש לנצל את הדרכים שקוברנטיס יודע לספק לנו כדי שהשירות שלנו יהיה עם יתירות וזמינות כמה שיותר גבוהות.
[…] יצרנו קונטיינר שירוץ בקוברנטיס, לאחר זמן קצר הוא יתחיל לרוץ באחד השרתים בקלאסטר. במאמר הקרוב נדבר על איך קורה הבחירה של השרת הדרכים השונות לבחור מקום ועוד. […]





[…] יצרנו קונטיינר שירוץ בקוברנטיס, לאחר זמן קצר הוא יתחיל לרוץ באחד השרתים בקלאסטר. במאמר הקרוב נדבר על איך קורה הבחירה של השרת הדרכים השונות לבחור מקום ועוד. […]