במאמר הקרוב נעסוק במשמעות והחשיבות של הניטור במערכת שלכם ואיך ניתן לעשות את זה באמצעות כלים שהם קוד פתוח בצורה מיטבית.
ניטור הוא אחד הדברים החשובים ב lifecycle (מחזור החיים) של כל מערכת. ניקח לדוגמא אפליקציה שרצה במשך זמן כל שהוא, יש הרבה תרחישים שיכולים לקרות, למשל באיזשהו שלב הדיסק שלו יתמלא ולא יהיה ניתן לאחסן או להריץ שום דבר עליו. דבר כזה יעלה לנו בזמן ואפילו בחוסר יציבות כשהמערכת לא זמינה למשתמשים.
אם יש לנו ניטור, נוכל לדעת באופן תמידי את מצב הדיסק, ולהגדיר ולקבל התראה כשהדיסק נמצא ב 80 אחוז תפוסה ולעשות פעולה אקטיבית כדי למנוע את המצב. למשל הגדלת הדיסק או ניקוי כלשהו.
פה נכנס לתמונה הכלי המדהים שנקרא prometheus, מדובר בכלי ניטור חינמי וקוד פתוח, המאפשר איסוף מטריקות(Metrics) מכל מקום שיחצין אותם.
Prometheus
בכדי לאסוף נתונים על מצב השרתים והאפליקציות שלנו אנחנו צריך מסד נתונים שיודע לאחסן את המידע הזה ואת הזמן של המידע. כלומר בשעה x מצב הדיסק היה y.
בשביל זה יש את prometheus מסד נתונים מסוג Time series שיודע לאסוף נתונים ולאחסן אותם בצורה יעילה.
מה היא מטריקה?
מטריקה הוא מדידה של חלק כלשהו בתוכנה או חומרה. למשל אחוז הדיסק הפנוי או כמות הקריאות שנעשו לאפליקציה.
ניתן להוסיף מטריקה בכל שפת תכנות בקוד שלנו בנקודות שאותן נרצה לדגום (ארחיב על כך במאמר הבא)
כשאנחנו רוצים ליצר מטריקות שיוכלו להיאסף ע”י prometheus צריך להחצין אותם בפורמט המתאים שהוא: שם המטריקה ומספר המיצג את הערך. למשל
remaining_disk_space_percent 36
המטריקה הזו תיאסף על ידי prometheus ותוכל לשמש אותנו לצורך יצירת התראות.
אחרי שהאפליקציה או השרת שלנו מיצא את המטריקה, נצטרך להגדיר ל prometheus לדגום את ה api שמחצין את המטריקות האלה והוא נקרא נקודת קצה (endpoint).
אז איך אומרים ל prometheus לנתר את ה מיקרו סרביסים שלנו?
נתחיל עם ההתקנה של prometheus בקוברנטיס.
ההתקנה המקובלת היא עם kube prometheus stack. ניתן להתקין אותה בקלות באמצעות Helm כפי שמופיע ב Readme של הפרויקט.
השלב הבא הוא לומר ל prometheus לנתר את המיקרו סרביס שלנו. נעשה את זה באמצעות ServiceMonitor שמגדיר ל prometheus איזה סרביס בקוברנטיס לנתר ואיך הוא יכול לגשת ל מטריקות שלו.
פה הגדרנו לעקוב אחרי סרביס serviceA בפורט http ובapi הדיפולטי שהוא metrics/ .
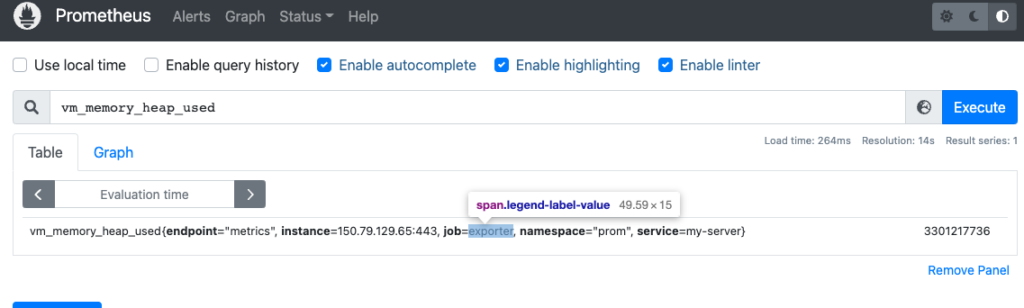
לאחק שנגדיר את ה ServiceMonitor נראה ב Prometheus את הנקודות קצה ואת המטריקות שהוא חושף.
למשל
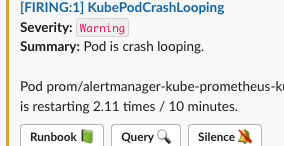
אחרי שיש לנו את המטריקות ב prometheus נרצה לקבל התראות על מטריקות עם ערך לא תקין. למשל אם אחוז הדיסק שנותר קטן מ 10% או שהסרביס שלנו מתרסט כל הזמן.
נעשה את זה באמצעות PrometheusRule. בתוך ההתראה נצטרך להגדיר איזה שאילתה ב prometheus מבטאת מצב שנרצה להתריע, מה לכתוב בהודעה של ההתרעה ולאן לשלוח את זה.
את ההתראות ניתן לקנפג שהם ישלחו למגוון מקומות הדוגמא הנפוצה היא slack.
אפשר לשלוח הותראות מבוססות טקסט
או אפילו לעצב את ההודעה עם הוראות לתפעול התקלה
Grafana
לאחר שאספנו את המטריקות והגדרנו התראות נרצה לעשות ויזואליזציה למצב ה מיקרו סרביסים שלנו והתשתית. בשביל זה נשתמש ב Grafana (ניתן בקלות להתקין דרך kube prometheus stack).
באמצעות Grafana נוכל לבנות תצוגה נוחה עם יכולת פילטור על מגוון מטריקות שנבחר. יש לה יכולת להוות ממשק מיל מגוון רחב של מסדי נתונים והיא מספקת יכולות ויזואליזציה שונות שנוכל לבנות dashboard אינפורמטיבי ומועיל.
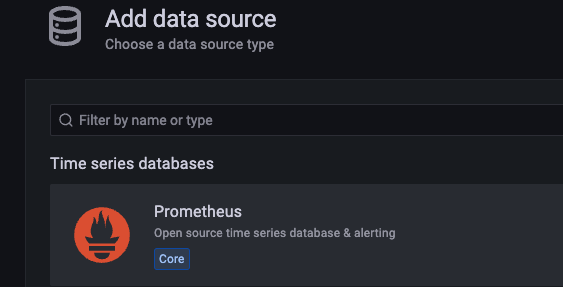
תחילה נגדיר את prometheus שלנו להיות המקור למידע שלנו, בכדי לעשות את זה נוסיף אותו כ data source ב Grafana.
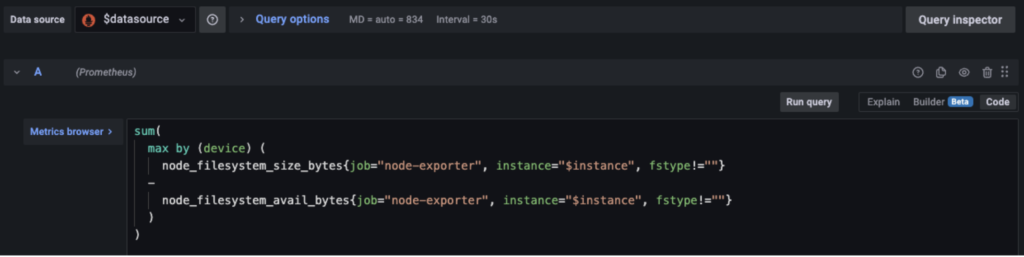
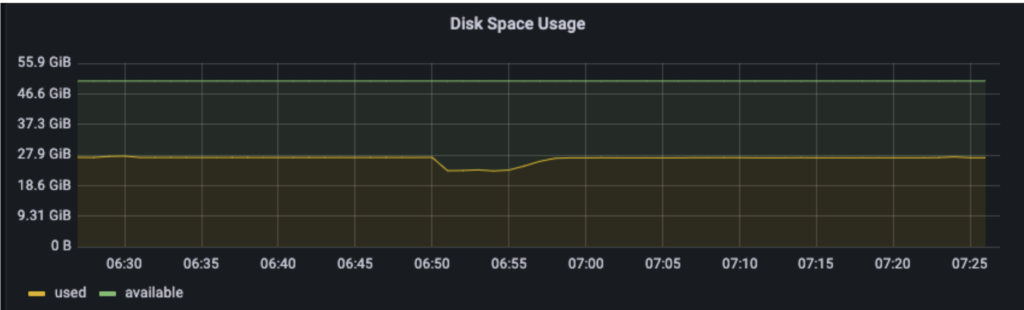
לאחר מכן נוכל לבנות תצוגה עם הנתונים שלנו. למשל אם נרצה לעקוב אחרי מילוי של דיסק נשתמש בגרף שנוכל לראות לאורך זמן את קצב ההתמלאות שלו. באמצעות שאילתא לPrometheus נוכל לעקוב אחרי קצב המילוי.
השאילתא הזו תתורגם בגרף למשהו כזה.
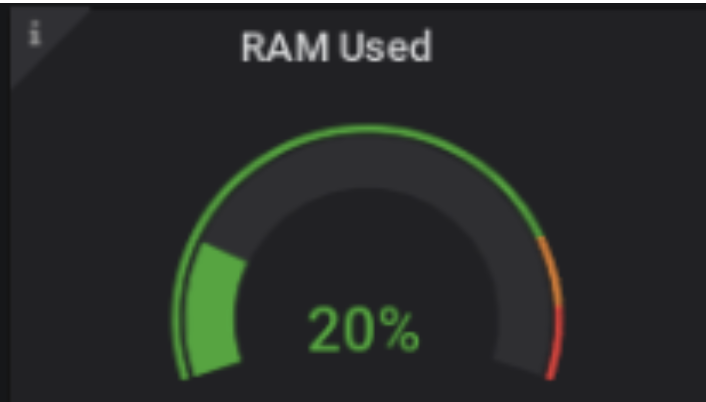
דוגמאות נוספות מאוד נפוצות הם stat לראות מצב של עובד/לא עובד ו Gauge לראות אחוזים למשל צריכת זיכרון.
לאחר שנקבץ כמות של מידע רלוונטי עבור שרת או כל דבר שאנחנו מנטרים ניצור dashboard שלם שיתן לנו את כל המידע שנרצה.
לרוב הדברים הסטנדרטיים ניתן בקלות למצוא דוגמאות ו dashboardים מוכנים בגיטהאב ובעיקר באתר של Grafana.
במאמר ראינו איך ניתן לאסוף מטריקות באמצעות Prometheus ו Grafana ולשלוח התראות כדי למנוע מצבים של מערכת לא זמינה. במאמר הבא נעסוק בכתיבת אפליקציה שמייצאת מטריקות.